
Arama motorlarında üst sıralarda yer almak için, içeriğin yanında kusursuz teknik SEO’ya sahip bir web sitesine sahip olmak gerekir. Web sitenizden en iyi şekilde yararlanmak ve rekabette üstünlük sağlamak istiyorsanız, teknik SEO’nun bazı temel bilgilerini öğrenmeniz bir zorunluluktur. Bu yazıda, teknik SEO’nun en önemli kavramlarından birini açıklayacağız: taranabilirlik.
Tarayıcı Nedir?
Google gibi bir arama motoru, bir tarayıcı, bir dizin ve bir algoritmadan oluşur. Crawler (tarayıcı) bağlantıları izler. Google’ın tarayıcısı web sitenizi bulduğunda içeriği okur ve içeriği dizine kaydeder.
Bir tarayıcı web üzerindeki bağlantıları izler. Tarayıcı aynı zamanda robot, bot veya örümcek adı ile de bilinir ve 7/24 internet üzerinde dolaşmaktadır. Bir web sitesi için indeks adı verilen, dev bir veritabanında sayfanın HTML sürümünü kaydeder. Bu indeks, tarayıcı web sitenizine her geldiğinde güncellenir ve yeni veya revize edilmiş bir sürümünü bulur. Google’ın sitenizi ne kadar önemli gördüğü ve web sitenizde yaptığınız değişikliklerin miktarına bağlı olarak, tarayıcı daha çok veya daha az sıklıkta sitenize uğrar.
Taranabilirlik nedir?
Taranabilirlik, Google’ın web sitenizi taraması ihtimalleriyle ilgilidir. Tarayıcılar sitenizden engellenebilir. Bir tarayıcıyı web sitenizden engellemek için birkaç yol vardır. Web siteniz veya web sitenizdeki bir sayfa bloke edilmişse, Google’ın tarayıcısına “buraya gelme” dediğiniz anlamına gelmektedir. Bu durumların çoğunda siteniz veya ilgili sayfa arama sonuçlarında görünmeyecektir.
Google’ın web sitenizi taramasını (veya indekslemesini) engelleyebilecek birkaç faktör daha vardır:
- Eğer robots.txt dosyanız tarayacıyıcı /indeksleyiciyi blokluyorsa, Google websitenize ya da engellenmiş spesifik sayfaya gelmeyecektir. Robots.txt dosyasıyla ilgili ve bu dosyanın nasıl oluşturulduğunu öğrenmek için semseo.com.tr’da yayınlanan Robots.txt Nedir ve Nasıl Oluşturulur? yazısını okuyabilirsiniz.
- Web sitenizi taramadan önce, tarayıcı sayfanızın HTTP üst bilgisine göz atacaktır. HTTP üst başlığı bir durum kodu içermektedir. Bu durum kodu bir sayfanın olmadığını bildirirse, Google web sitenizi taramayacaktır.
- Eğer belli bir sayfadaki robots meta tag arama motorunu o sayfa için indeksleme yapmasında engelliyorsa, Google o sayfayı tarayacaktır ancak indekslemeyecek yani dizinine eklemeyecektir.
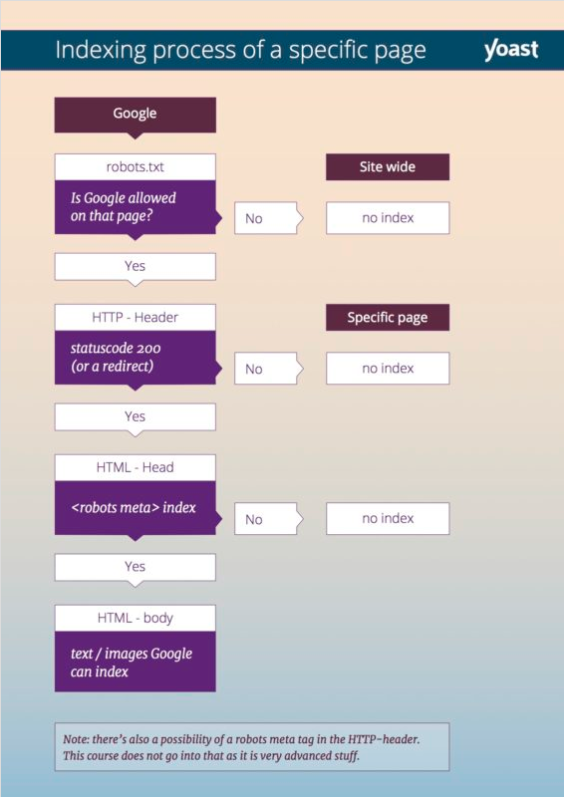
Yoast’ta yayınlanan akış şeması, bir sayfayı dizine eklemeye çalışırken botların takip ettiği işlemi anlamanıza yardımcı olabilir:
Bunlarla birlikte, eğer tarayacıları engellerseniz – belki de bilmeden -, asla Google’da yüksek sıralama elde edemezsiniz. Eğer, SEO konusunda ciddi iseniz, bu sizin için hayata geçirilmesi ve hakkında detaylı bilgiler edinilmesi gereken oldukça önemli bir konudur.



